
loc
Types representing line and column positions and ranges in text files.
https://github.com/chris-martin/loc
| Version on this page: | 0.1.3.4 |
| LTS Haskell 22.30: | 0.2.0.0 |
| Stackage Nightly 2023-12-26: | 0.2.0.0 |
| Latest on Hackage: | 0.2.0.0 |
loc-0.1.3.4@sha256:a020d51592ea68bf2eccb92a8450b914dac4a7fa64422568b11bcd65cdd9b2d7,1960Module documentation for 0.1.3.4
loc
Overview of the concepts:
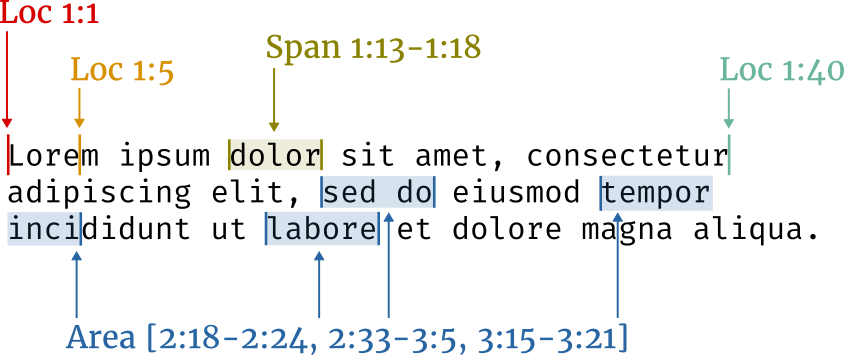
Loc- a cursor position, starting at the origin1:1Span- a nonempty contiguous region between two locsArea- a set of zero or more spans with gaps between them
See also:
- loc-test - Test-related utilities for this package.
Pos
Since all of the numbers we’re dealing with in this domain are positive, we
define a “positive integer” type. This is a newtype for Natural that doesn’t
allow zero.
newtype Pos = Pos Natural
deriving (Eq, Ord)
instance Num Pos where
fromInteger = Pos . checkForUnderflow . fromInteger
Pos x + Pos y = Pos (x + y)
Pos x - Pos y = Pos (checkForUnderflow (x - y))
Pos x * Pos y = Pos (x * y)
abs = id
signum _ = Pos 1
negate _ = throw Underflow
checkForUnderflow :: Natural -> Natural
checkForUnderflow n =
if n == 0 then throw Underflow else n
Pos does not have an Integral instance, because that would require
implementing quotRem :: Pos -> Pos -> (Pos, Pos), which doesn’t make much
sense. Therefore we can’t use toInteger on Pos. Instead we use our own
ToNat class to convert positive numbers to natural numbers.
class ToNat a where
toNat :: a -> Natural
instance ToNat Pos where
toNat (Pos n) = n
Line, Column
We then add some newtypes to be more specific about whether we’re talking about line or column numbers.
newtype Line = Line Pos
deriving (Eq, Ord, Num, Real, Enum, ToNat)
newtype Column = Column Pos
deriving (Eq, Ord, Num, Real, Enum, ToNat)
Loc
A Loc is a Line and a Column.
data Loc = Loc
{ line :: Line
, column :: Column
}
deriving (Eq, Ord)
Note that this library has chosen to be remain entirely agnostic of the text
that the positions are referring to. Therefore there is no “plus one” operation
on Loc, because the next Loc after 4:17 could be either 4:18 or 5:1 -
we can’t tell without knowing the line lengths.
Span
A Span is a start Loc and an end Loc.
data Span = Span
{ start :: Loc
, end :: Loc
} deriving (Eq, Ord)
A Span is not allowed to be empty; in other words, start and end must be
different.
There are two functions for constructing a Span. They both reorder their
arguments as appropriate to make sure the start comes before the end (so that
spans are never backwards). They take different approaches to ensuring that
spans are never empty: the first can throw an exception, whereas the second is
typed as Maybe.
fromTo :: Loc -> Loc -> Span
fromTo a b =
maybe (throw EmptySpan) id (fromToMay a b)
fromToMay :: Loc -> Loc -> Maybe Span
fromToMay a b =
case compare a b of
LT -> Just (Span a b)
GT -> Just (Span b a)
EQ -> Nothing
The choice to use an exclusive upper bound [start, end) rather than two inclusive bounds [start, end] is forced by the decision to be text-agnostic. With inclusive ranges, you couldn’t tell whether span 4:16-4:17 abuts span 5:1-5:2 without knowing whether the character at position 4:17 is a newline.
Area
Conceptually, an area is a set of spans. To support efficient union and
difference operations, Area is defined like this:
data Terminus = Start | End
deriving (Eq, Ord)
newtype Area = Area (Map Loc Terminus)
deriving (Eq, Ord)
You can think of this as a sorted list of the spans’ start and end positions, along with a tag indicating whether each is a start or an end.
Show
We define custom Show and Read instances to be able to write terse
doctests like
>>> addSpan (read "1:1-6:1") (read "[1:1-3:1,6:1-6:2,7:4-7:5]")
[1:1-6:2,7:4-7:5]
These are the showsPrec implementations for Loc and Span:
locShowsPrec :: Int -> Loc -> ShowS
locShowsPrec _ (Loc l c) =
shows l .
showString ":" .
shows c
spanShowsPrec :: Int -> Span -> ShowS
spanShowsPrec _ (Span a b) =
locShowsPrec 10 a .
showString "-" .
locShowsPrec 10 b
Read
The parser for Pos is based on the parser for Natural, applying mfilter (/= 0) to make the parser fail if the input represents a zero.
posReadPrec :: ReadPrec Pos
posReadPrec =
Pos <$> mfilter (/= 0) readPrec
As a reminder, the type of mfilter is:
mfilter :: MonadPlus m => (a -> Bool) -> m a -> m a
The Loc parser uses a very typical Applicative pattern:
-- | Parses a single specific character.
readPrecChar :: Char -> ReadPrec ()
readPrecChar = void . readP_to_Prec . const . ReadP.char
locReadPrec :: ReadPrec Loc
locReadPrec =
Loc <$>
readPrec <*
readPrecChar ':' <*>
readPrec
We used mfilter above to introduce failure into the Pos parser; for Span
we use empty.
empty :: Alternative f => f a
First we use fromToMay to produce a Maybe Span, and then in the case where
the result is Nothing we use empty to make the parser fail.
spanReadPrec :: ReadPrec Span
spanReadPrec =
locReadPrec >>= \a ->
readPrecChar '-' *>
locReadPrec >>= \b ->
maybe empty pure (fromToMay a b)
Comparison to similar packages
srcloc
srcloc has a similar general purpose: defining types related to positions in text files.
Some differences:
srcloc‘sPostype (comparable to ourLoctype) has aFilePathparameter, whereas this library doesn’t consider file paths at all.srclochas nothing comparable to theAreatype.
There are some undocumented aspects of srcloc we find confusing:
- What does “character offset” mean?
- Does
srcloc’sLoctype use inclusive or exclusive bounds?