
hspec-tidy-formatter
A custom hspec formatter for easy-to-read terminal output.
https://github.com/carlwr/hspec-tidy-formatter#readme
| Stackage Nightly 2026-07-22: | 0.2.0.1 |
| Latest on Hackage: | 0.2.0.1 |
hspec-tidy-formatter-0.2.0.1@sha256:04ff66c1c266127ca39de1dc00e433b920c95f67f0be268211dbd04fcdc50699,4898Module documentation for 0.2.0.1
- Test
hspec-tidy-formatter
A custom hspec formatter for terminal output.


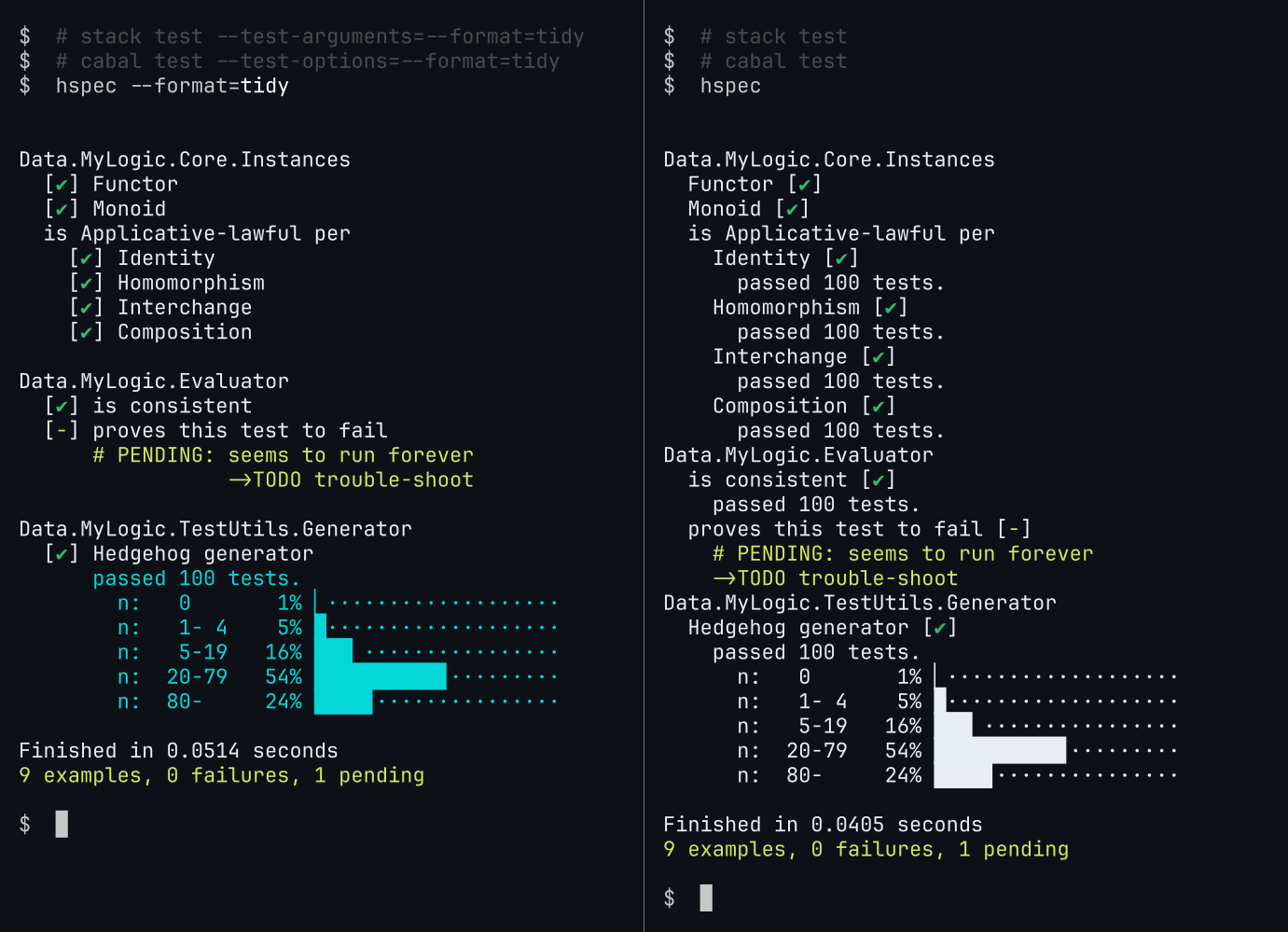
The formatter should work with with any test runner backend. It may be particularly useful with Hedgehog tests through hspec-hedgehog: it omits the “passed 100 tests.” otherwise printed after each spec item, yet includes manually added test output (Hedgehog.collect, Hedgehog.label etc.).
How to enable
With hspec-discover
Place a file SpecHook.hs in the source directory of the test component:
-- --- test/SpecHook.hs ---
import Test.Hspec
import qualified Test.Hspec.TidyFormatter as TidyFormatter
hook :: Spec -> Spec
-- use by default:
hook = TidyFormatter.use
-- to instead use only if requested (`hspec --format=tidy`):
-- hook = TidyFormatter.register
hspec --help can be used to inspect which formatters hspec is aware of:
$ cabal test hspec --test-options=--help | grep -A3 FORMATTER
FORMATTER OPTIONS
-f NAME --format=NAME use a custom formatter; can be one of
- checks, specdoc, progress,
+ checks, specdoc, progress, tidy
failed-examples or silent
By modifying Spec-s directly
main :: IO ()
main = hspec . TidyFormatter.use $ spec
spec :: Spec
spec = it "adds" $ 1+1 `shouldBe` (2::Int)
Functionality, options
-
supports transient output/progress
-
handles multiline spec tree strings gracefully
- transient/progress output only prints the first line in case of multiline strings
- the eventual non-transient output prints all lines, properly indented
-
honors most
hspecoptions, including:--times,--no-unicode,--no-color,--print-cpu-time,--print-slow-items=[=N]
Printing of additional text from test runners
hspec allows test runners to pass it additional text together with the outcome of each test. This formatter, by default, prints such text only if it spans more than one line. To instead print all such text unconditionally, use --times (default: --no-times). This will additionally do what this option is originally supposed to do: print the execution time for spec items (if > 0 after rounding to milliseconds).
E.g. with hspec-hedgehog, which passes the number of tests run for each item as a single line of text:
- $ hspec --format=tidy
+ $ hspec --format=tidy --times
[...]
is Applicative-lawful per
- [✔] Identity
+ [✔] Identity (21ms) (passed 100 tests.)
To instead suppress the printing of any additional text from the test runner, use --expert (default: --no-expert).
Verbosity switches --[no-]expert, --[no-]times combinations
For two spec items whose test runner returns a single line, and a few lines, respectively, of additional text:
=========== =========================================
<ARGS> `hspec <ARGS>` example output
=========== =========================================
(most verbose)
----------- -----------------------------------------
--times [✔] Identity (21ms) (passed 100 tests.)
--no-expert [✔] Hedgehog generator (49ms)
passed 100 tests.
n: 0 1% ▏···················
n: 1- 4 5% █···················
n: 5-19 16% ███▏················
----------- -----------------------------------------
--no-times [✔] Identity
--no-expert [✔] Hedgehog generator
(DEFAULT) passed 100 tests.
n: 0 1% ▏···················
n: 1- 4 5% █···················
n: 5-19 16% ███▏················
----------- -----------------------------------------
--times [✔] Identity (21ms)
--expert [✔] Hedgehog generator (49ms)
----------- -----------------------------------------
--no-times [✔] Identity
--expert [✔] Hedgehog generator
(least verbose)
Written by a human
During the development of this package, AI models were used extensively for discussions and feedback. All code and documentation however is authored by me (Carl), a human developer: no text (code; natural language) within this package/repo is direct output from an AI model.
Since I am not a native English speaker, any natural language is likely to feature language quirks. AI models were not asked to identify or rectify such.
The above should not be understood as any opinion or even preference of mine - I both use and value development with higher degrees of AI autonomy than what was used in this project.